
【有梗學習】111文化學習講座紀錄-學習歷程與數據科學
撰文/廖冠智 所長 日期/112年04月15日
#學習歷程與數據科學
#學習揹包裡的秘密
學校想要培育出什麼樣的學生?產業想要找尋什麼樣的員工?學校之目的在培育人才的素養,產業之目的在尋找人才之職能。在素養與職能之間,皆清楚指涉到Competence意義,一個暗指是學生內化知識內容與生活結合的KSA(Knowledge, Skill and Attribute)能力,另一個暗指員工對工作內容的勝任能力,無論解釋為素養或職能,從一個大型工廠的製造流程來看,人才規格的模組化與標準化,有利於大量複製的產製需求,產品卻僅有共同特質卻不具獨特性,因而才有產品客製化的需要。
然而,若將學校視為一座人才製造工廠,產品產量大且製造迅速,然而產業是否願意直接收購、又如何收購哪些產品,不僅是產業所苦惱的地方,也是學校正極力想改變的困境,更是現在的台灣所面臨的窘境。
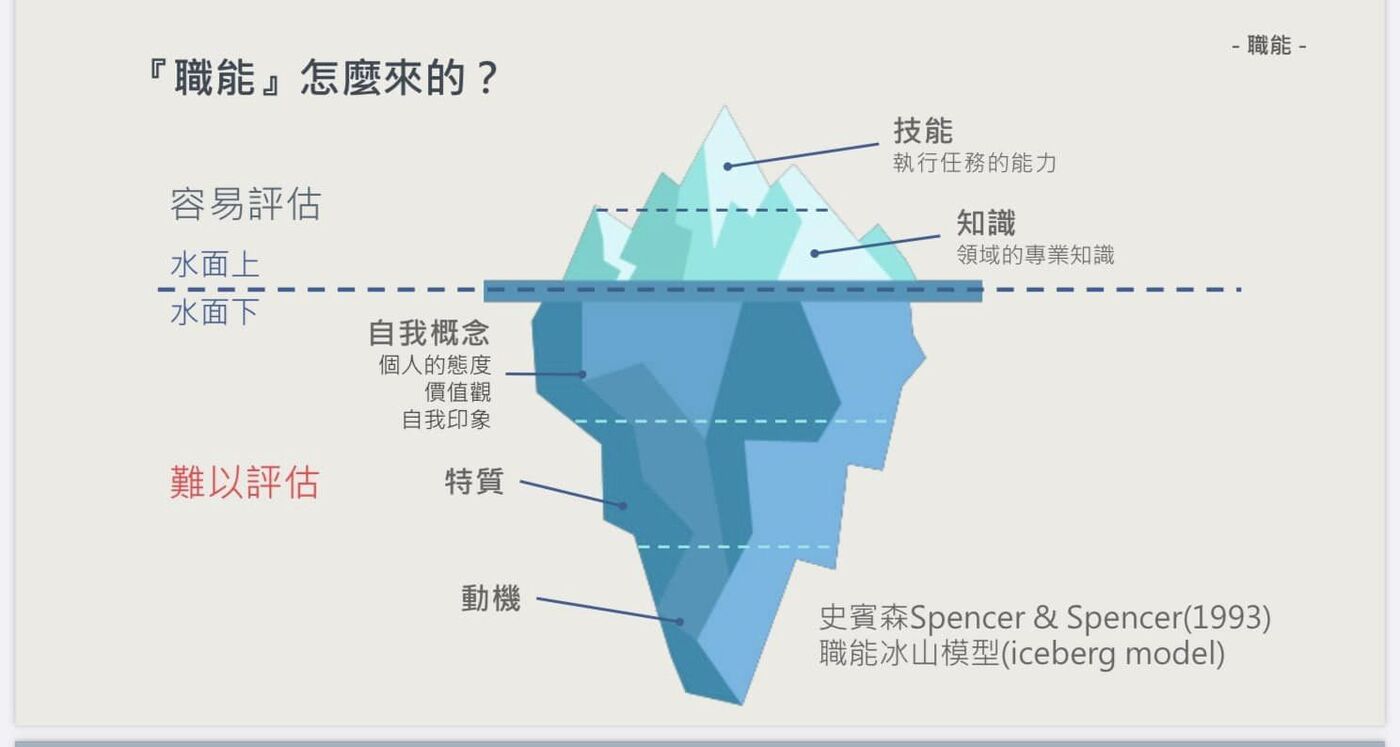
前半段講座,資策會蔡承洋組長試著以冰山理論解構『職能』的定義,水面上的冰山是看得見的技能(執行任務的能力),與知識(領域專業知識),容易評估得知。相較於水面下的冰山是不易得知的自我概念(態度與價值觀等)、人格特質與動機等。當然,各國依照各自國家需要與社會結構訂定所需要的職能目標,明確的職能目標除了作為教育與訓練方向參考設計之外,幫助勞工因應環境變遷獲取相應技能,進而提升勞動市場的生產力,甚至是提升個人職涯規劃與學習目標,有的是國家與國家之間的競合關係,作為促進國際人才流動之目的。
承洋從政府法人的角度分享一個產業職能的訂定程序,首先從職能專家訪談瞭解工作內容,成立涵蓋產學研的專家小組,會議討論KSA職能內涵,並進一步以量化的職能基準驗證問卷、質化的職能專家交叉驗證後,最後將職能基準定稿,前後歷時大約8~10個月,且每一職能平均每三年一次公告是否有維護更新的必要。聽到這裡,是不是發現這埸的產業職能基準訂定程序乃從top-down模式從上到下進行,似乎有好的建構效度(construct validity),卻未必具有良好的內容效度(content validity)?更值得思考的是,學校端如何將職能基準作為訓練課程,以作為產業能用的人才,也是UCAN大專校院就業職能平台的設計意義;抑或者產業希望透過定義出職能輪廓,不僅作為人才招募的依據,也是人才晉升的準則。
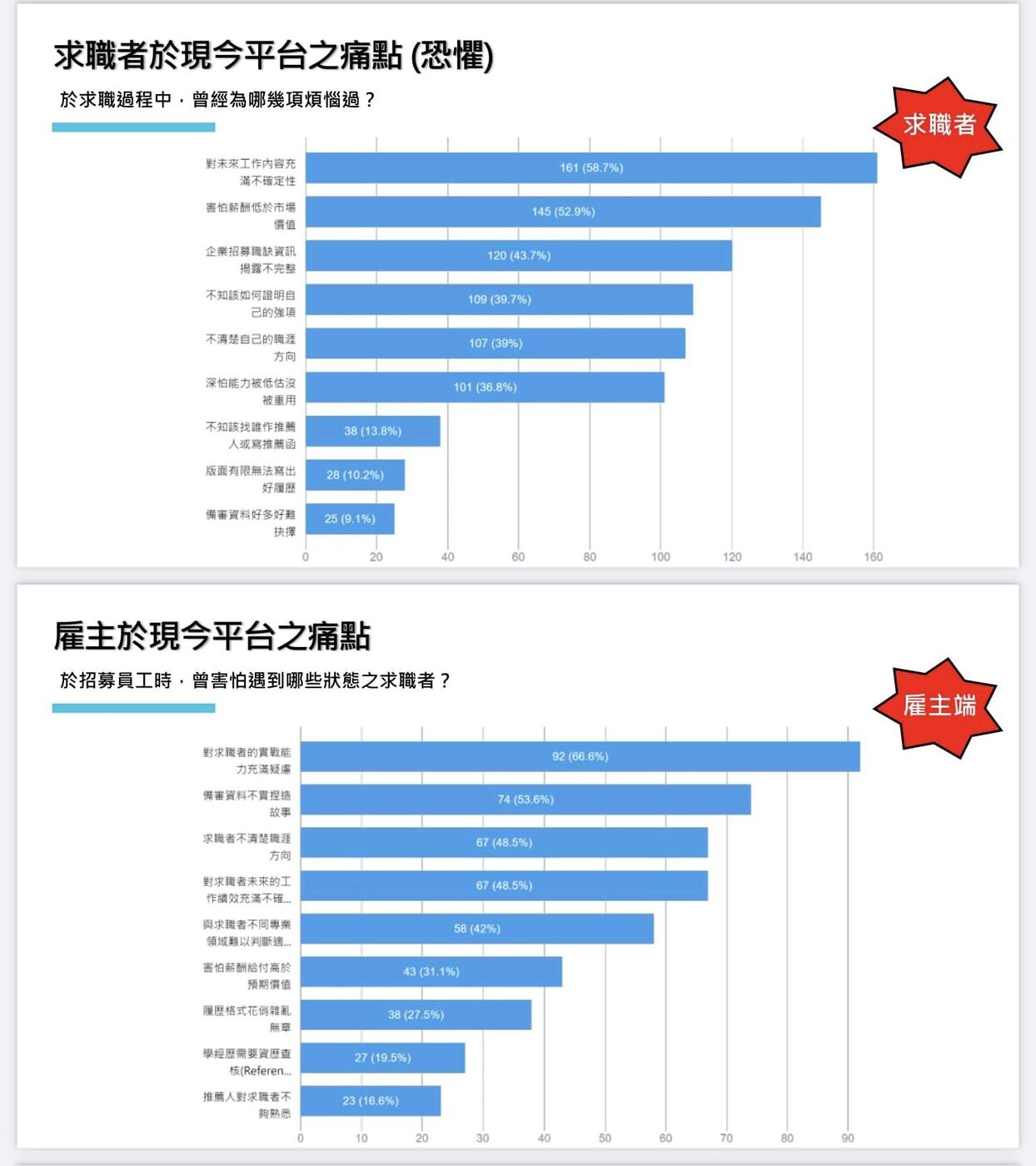
職能需要因應環境變化而更迭累積,在什麼時間點需要取得什麼型式的職能、如何取得等,以紀錄歷程呈現,充分掌握到員工在職能的學習變遷,如同108課綱發展至今,學習歷程的設計原意本就期盼學生將自發性學習內容,整理出相應的學習表現,以紀錄學習過程反映成長軌跡、人格特質,就像是寫出學習日誌,從日誌中反思出自己的現狀,乃推展出自己可能的走向,當然如同演講摘要中所述,在現實生活中,很少有人會思考如何紀錄自己的學習歷程以及職業生涯的發展軌跡,或者說學習歷程發展至今,多半不是學生因為自發性的學習,而有歷程檔案的整理,而是為了需上傳繳交歷程檔案,才擬造出學習的議題、場域與情境等倒果為因。
倘若紀錄學習時,像是寫日記的效果一樣,你會不會因為寫了這些日記而更了解自己,或者更清楚、有機會自省自己當下的態度?我們從浪漫的角度來思考,『情書』宛如是學習愛一個人的『歷程檔案』,無論情書最後有無寄出,你不會為了“寫好情書”而去“愛一個人“,而是在真正愛上一個人後,你才會想寫下千言萬語。所以,學習歷程本意是希望你想真心愛一個人所寫下的情書,如同你專注在某一領域的學習時才整理出來的歷程檔案。然而,寫情書有很大的內在動機:渴望愛人與被愛,整理歷程檔案多半是有目的的需要:證明自己有能力被錄取😆。
至於學習歷程檔案,具有什麼樣的意義?這玩意或許從數據科學的分析角度裡,以具有長時間維度所呈現的資料樣式中能找到靈感。講座後半段,工研院產業學院的游函諺經理,帶來三個面向,分別為:人才養成計畫數據(digi talent數位人才學習履歷分析)、AI履歷多模態媒合(多元型態且非結構化資料數據)、賽局理論分析人才招募行為的數據科學研究專案(破解人才供需招募行為中的資訊不對稱因素)的案例分享。
函諺從數據集的蒐集與分析中,說明在學期間實習未來就業是否有幫助,從所收到的學生履歷獲得分數、在學學系的類別組、實習專題的研習領域、最高畢業學歷的四項資料,搭配KNN、Decision tree、Random forest、SVM機器學習方法,進一步推薦學生適合的研習領域,從成果中得知已達八成準確判斷就業職務類別的傾向,同時想從事的職稱類別也有7-8成提供適切的研習路徑建議。
函諺另外分享了AI作為履歷媒合平台的應用,進一步分析人臉面相的多模態資料,以人臉校正、特徵點(距離)預測、大樹法與分類等方式,結合面相的知識資料,來作為智能職務媒合平台的框架,特別的是應用在模擬面試,透過分析人臉視覺影像、聲音與文本特徵進行綜合評估,提供給面試者與求職者參考。
從前面提到履歷資料蒐集、AI面試,再到人才招募的實際問題,函諺最後分享人才供需招募行為裡充滿資訊不對稱的問題,如何由第三方影響者(influencer)來降低雙方焦慮的作法。從蒐集的數據集中得知,扮演第三方influencer因素為具備相似的價值觀與職業目標、認識求職者並獲得信任支持、本身所具有的產業專業與工作經驗等。
學習歷程與數據科學,這兩者所交集處,應是認識在學習過程中,將會有什麼樣的學習足跡?而足跡將是什麼樣型態的資料內容,這勢必為多模態的非結構數據集形式,真正值得我們思考的是,在學習行為發生的當下,將會生成哪些資料,特別是如何蒐集這些資料,才有能作為數據集的可能,學習的行爲不僅是看讀寫,或者數位世界裡的操作點選或登入停留的時間,包含互動社交的歷程,對話交談內容等,一旦足跡產生便進行蒐集,即是我所認為學習戳記(learning stamp)的概念:學習行為下的資料註記內容,將一連串學習行為發生的資料,以戳記型態紀錄,作為數據內容分析的基準,且具備連續、即時、原始的形式,才能彰顯學習歷程的實質意義,免於過於裝飾歷程檔案的面試文化。
學習戳記其實也是源於一份2018年發佈的研究報告「Data Backpacks: Portable Records & Learner Profiles」中提及數據揹包(data backpack)的概念,可說是將學習揹包(Learning Backpack)與學習者輪廓側寫(Learner Profile)首次匯聚的開始,這概念始自the Center for Research on Education Outcomes (CREDO) at Stanford University的Margaret Raymond 在2012年時第一次提到The Student Data Backpack的想法,當學習型式持續朝向個人化發展、貼近每一學習者的需求時,更需要有學習揹包與學習者輪廓檔案來支持與增強個人化與保護隱私。
回到先前我們所提,假使把自主學習的過程當成一場個人遠足,你會為這次遠足準備什麼?準備自己的學習揹包,能在學習剛開始時,確立學習會有什麼需求,而學習者輪廓檔案能作為學習持續增強、補足與擴充方向的參考,讓學習者更掌握自己的學習過程,為自己未來的職能做準備。
學習揹包裡究竟裝什麼?我想,會像是自助背包客一樣,只帶上學習的必需品:學習動機、學習興趣,你所習慣且善用的學習工具,一切輕便為主,機動為佳,還要有一台好相機,紀錄你當下的學習戳記,即便沒有地圖指引,你也可以讓自己四處冒險,長時間之下的旅行足跡,將令人值得回味,更是一串串值得珍藏的回憶。🙂
謝謝函諺、承洋帶來十分值得思考的講座,也很開心進一步讓學科所研究生的教育新創事業有新合作方式,期待能開花結果❤️
👍
#學習歷程與數據科學
#學習揹包裡的秘密
學校想要培育出什麼樣的學生?產業想要找尋什麼樣的員工?學校之目的在培育人才的素養,產業之目的在尋找人才之職能。在素養與職能之間,皆清楚指涉到Competence意義,一個暗指是學生內化知識內容與生活結合的KSA(Knowledge, Skill and Attribute)能力,另一個暗指員工對工作內容的勝任能力,無論解釋為素養或職能,從一個大型工廠的製造流程來看,人才規格的模組化與標準化,有利於大量複製的產製需求,產品卻僅有共同特質卻不具獨特性,因而才有產品客製化的需要。
然而,若將學校視為一座人才製造工廠,產品產量大且製造迅速,然而產業是否願意直接收購、又如何收購哪些產品,不僅是產業所苦惱的地方,也是學校正極力想改變的困境,更是現在的台灣所面臨的窘境。
前半段講座,資策會蔡承洋組長試著以冰山理論解構『職能』的定義,水面上的冰山是看得見的技能(執行任務的能力),與知識(領域專業知識),容易評估得知。相較於水面下的冰山是不易得知的自我概念(態度與價值觀等)、人格特質與動機等。當然,各國依照各自國家需要與社會結構訂定所需要的職能目標,明確的職能目標除了作為教育與訓練方向參考設計之外,幫助勞工因應環境變遷獲取相應技能,進而提升勞動市場的生產力,甚至是提升個人職涯規劃與學習目標,有的是國家與國家之間的競合關係,作為促進國際人才流動之目的。
承洋從政府法人的角度分享一個產業職能的訂定程序,首先從職能專家訪談瞭解工作內容,成立涵蓋產學研的專家小組,會議討論KSA職能內涵,並進一步以量化的職能基準驗證問卷、質化的職能專家交叉驗證後,最後將職能基準定稿,前後歷時大約8~10個月,且每一職能平均每三年一次公告是否有維護更新的必要。聽到這裡,是不是發現這埸的產業職能基準訂定程序乃從top-down模式從上到下進行,似乎有好的建構效度(construct validity),卻未必具有良好的內容效度(content validity)?更值得思考的是,學校端如何將職能基準作為訓練課程,以作為產業能用的人才,也是UCAN大專校院就業職能平台的設計意義;抑或者產業希望透過定義出職能輪廓,不僅作為人才招募的依據,也是人才晉升的準則。
職能需要因應環境變化而更迭累積,在什麼時間點需要取得什麼型式的職能、如何取得等,以紀錄歷程呈現,充分掌握到員工在職能的學習變遷,如同108課綱發展至今,學習歷程的設計原意本就期盼學生將自發性學習內容,整理出相應的學習表現,以紀錄學習過程反映成長軌跡、人格特質,就像是寫出學習日誌,從日誌中反思出自己的現狀,乃推展出自己可能的走向,當然如同演講摘要中所述,在現實生活中,很少有人會思考如何紀錄自己的學習歷程以及職業生涯的發展軌跡,或者說學習歷程發展至今,多半不是學生因為自發性的學習,而有歷程檔案的整理,而是為了需上傳繳交歷程檔案,才擬造出學習的議題、場域與情境等倒果為因。
倘若紀錄學習時,像是寫日記的效果一樣,你會不會因為寫了這些日記而更了解自己,或者更清楚、有機會自省自己當下的態度?我們從浪漫的角度來思考,『情書』宛如是學習愛一個人的『歷程檔案』,無論情書最後有無寄出,你不會為了“寫好情書”而去“愛一個人“,而是在真正愛上一個人後,你才會想寫下千言萬語。所以,學習歷程本意是希望你想真心愛一個人所寫下的情書,如同你專注在某一領域的學習時才整理出來的歷程檔案。然而,寫情書有很大的內在動機:渴望愛人與被愛,整理歷程檔案多半是有目的的需要:證明自己有能力被錄取😆。
至於學習歷程檔案,具有什麼樣的意義?這玩意或許從數據科學的分析角度裡,以具有長時間維度所呈現的資料樣式中能找到靈感。講座後半段,工研院產業學院的游函諺經理,帶來三個面向,分別為:人才養成計畫數據(digi talent數位人才學習履歷分析)、AI履歷多模態媒合(多元型態且非結構化資料數據)、賽局理論分析人才招募行為的數據科學研究專案(破解人才供需招募行為中的資訊不對稱因素)的案例分享。
函諺從數據集的蒐集與分析中,說明在學期間實習未來就業是否有幫助,從所收到的學生履歷獲得分數、在學學系的類別組、實習專題的研習領域、最高畢業學歷的四項資料,搭配KNN、Decision tree、Random forest、SVM機器學習方法,進一步推薦學生適合的研習領域,從成果中得知已達八成準確判斷就業職務類別的傾向,同時想從事的職稱類別也有7-8成提供適切的研習路徑建議。
函諺另外分享了AI作為履歷媒合平台的應用,進一步分析人臉面相的多模態資料,以人臉校正、特徵點(距離)預測、大樹法與分類等方式,結合面相的知識資料,來作為智能職務媒合平台的框架,特別的是應用在模擬面試,透過分析人臉視覺影像、聲音與文本特徵進行綜合評估,提供給面試者與求職者參考。
從前面提到履歷資料蒐集、AI面試,再到人才招募的實際問題,函諺最後分享人才供需招募行為裡充滿資訊不對稱的問題,如何由第三方影響者(influencer)來降低雙方焦慮的作法。從蒐集的數據集中得知,扮演第三方influencer因素為具備相似的價值觀與職業目標、認識求職者並獲得信任支持、本身所具有的產業專業與工作經驗等。
學習歷程與數據科學,這兩者所交集處,應是認識在學習過程中,將會有什麼樣的學習足跡?而足跡將是什麼樣型態的資料內容,這勢必為多模態的非結構數據集形式,真正值得我們思考的是,在學習行為發生的當下,將會生成哪些資料,特別是如何蒐集這些資料,才有能作為數據集的可能,學習的行爲不僅是看讀寫,或者數位世界裡的操作點選或登入停留的時間,包含互動社交的歷程,對話交談內容等,一旦足跡產生便進行蒐集,即是我所認為學習戳記(learning stamp)的概念:學習行為下的資料註記內容,將一連串學習行為發生的資料,以戳記型態紀錄,作為數據內容分析的基準,且具備連續、即時、原始的形式,才能彰顯學習歷程的實質意義,免於過於裝飾歷程檔案的面試文化。
學習戳記其實也是源於一份2018年發佈的研究報告「Data Backpacks: Portable Records & Learner Profiles」中提及數據揹包(data backpack)的概念,可說是將學習揹包(Learning Backpack)與學習者輪廓側寫(Learner Profile)首次匯聚的開始,這概念始自the Center for Research on Education Outcomes (CREDO) at Stanford University的Margaret Raymond 在2012年時第一次提到The Student Data Backpack的想法,當學習型式持續朝向個人化發展、貼近每一學習者的需求時,更需要有學習揹包與學習者輪廓檔案來支持與增強個人化與保護隱私。
回到先前我們所提,假使把自主學習的過程當成一場個人遠足,你會為這次遠足準備什麼?準備自己的學習揹包,能在學習剛開始時,確立學習會有什麼需求,而學習者輪廓檔案能作為學習持續增強、補足與擴充方向的參考,讓學習者更掌握自己的學習過程,為自己未來的職能做準備。
學習揹包裡究竟裝什麼?我想,會像是自助背包客一樣,只帶上學習的必需品:學習動機、學習興趣,你所習慣且善用的學習工具,一切輕便為主,機動為佳,還要有一台好相機,紀錄你當下的學習戳記,即便沒有地圖指引,你也可以讓自己四處冒險,長時間之下的旅行足跡,將令人值得回味,更是一串串值得珍藏的回憶。🙂
謝謝函諺、承洋帶來十分值得思考的講座,也很開心進一步讓學科所研究生的教育新創事業有新合作方式,期待能開花結果❤️
👍






瀏覽數:
